Summary: Data can be processed in parallel by using multiple threads on a single CPU or by passing code to the data in systems like the Hadoop Distributed File System.
Imagine you’re driving your car on the way to work. You keep an eye on the road ahead, the side mirrors, the rearview mirror, and even what’s on the radio.
You’re changing the channel on the radio and you like the song but not sure if you want to stay on this station. Suddenly, a car pulls up from behind you and moves into your blind spot. While the music still plays in the background, you see him start veering into your lane. You deftly avoid a mild collision and, after a second to compose yourself, you go back to scanning for a good song on the radio.
A Single CPU with Multiple Threads
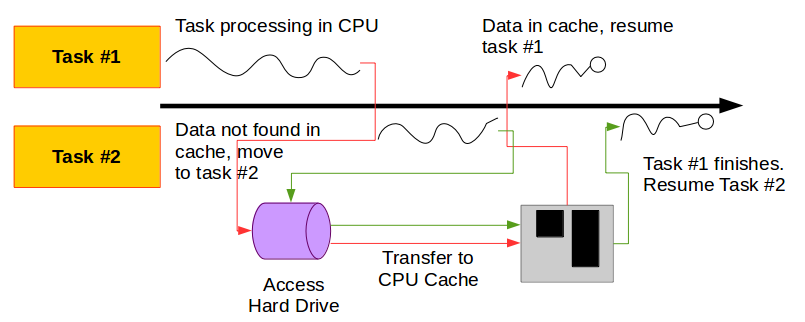
Parallel processing on a single CPU follows a similar but less concerning path.
The CPU is the brain of your computer. It does all of the processing from running your operating system to doing calculations for your deep neural network. All of this processing is done by executing commands at a mind-numbingly fast pace.
However, a single CPU needs to get its data to process from somewhere. A CPU looks for data in a few places. In order from last to first…
- Hard Drive: Slow to access, last to search
- RAM: Faster to access
- CPU Cache: Fastest to access, first to seearch
If the CPU can’t find the data it needs in the cache, it moves up the storage hierarchy. As a result, your processing stops as the data is being pulled. A multithreaded CPU, which most modern chips are, can multitask while waiting.
When a task is not running due to waiting for data, a new task can be started and ran until it completes or needs data from outside the cache. Usually you have twice as many threads as the number of cores on your CPU.
Back to the driving example, you really can only do one thing at a time while driving. You can look ahead, to the side, or behind you or you can start scanning the radio for a good song. We do these things very quickly, but for milliseconds, your attention has to be focused on only one of these things.
The same idea applies to CPU tasks. One task stops, the other one picks up where it left off. As another car pulls out from behind you, your attention is diverted to that car. Once that care passes you (safely) your attention returns to the road ahead of you.
Your attention likely flits back and forth between the car passing you and the road ahead of you. You can think of this as your brain waiting for more data and thus turning its attention to the next task that’s ready.
Back to the technical details…
This same process applies to having multiple cores on your CPU.
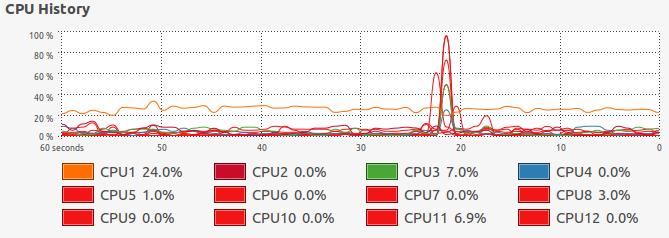
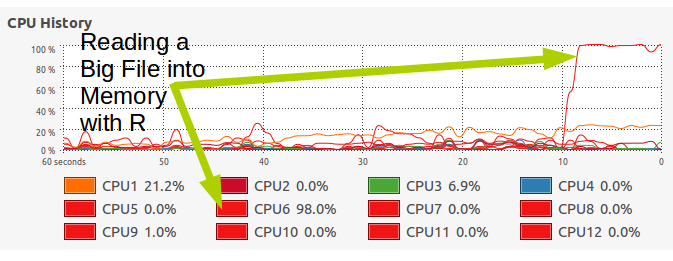
My personal PC has 6 cores but 12 threads. This allows me to do an incredible amount of processing in a short amount of time. However, if the algorithm or process isn’t designed to be done across multiple cores, I’m stuck with running on a single thread…
Parallel Processing Across Multiple Machines
When you involve multiple machines you can cut the processing time down. Instead of relying on one machine and maybe the multi threading capability, you can distribute the work across many machines.
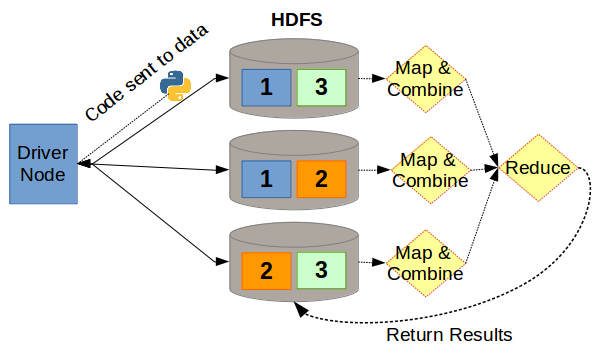
The Hadoop Distributed File System (HDFS) is an example where you are sending code to multiple machines. This differs from what a normal PC file system does.
- The CPU is essentially the driver
- A regular PC will move data from disk to cache
- Then the CPU continues its program with the new data
Distributed computing instead has lots of data stored on multiple machines and the processing instructions are sent to those machines. This decreases the amount of time spent moving data around.
The only trick is that each computer in HDFS only has a part of the data and thus needs to eventually send their data (hopefully aggregated in some way) across the network to be further refined (or reduced) into what the user wants.
Intuitively, letting more machines, which have more CPUs, do the work makes sense. If you have so much data and have a lot of processing needs, you can add more machines to potentially speed up the processing.
Some examples of useful applications of distributed computing:
- Matrix Multiplication: Classic example. Take chunks of a matrix A and multiply it by the corresponding parts of matrix B. This creates smaller chunks of data and you can combine them on one machine.
- Training Multiple Models: If you’re building an ensemble, you can build one model on one machine and another on the next. Then, once they’re all trained, you can bring them back to one machine for prediction.
- Iterating Through Lots of Settings: If you need to brute force your way through something, like trying hundreds of different parameters in an algorithm, you can send the task to multiple machines and it will be obviously faster than building the models one at a time.
Some examples where adding more machines won’t be much help:
- Calculate the Median (or any specific percentile): In order to calculate the median, you need to sort the data and find the middle value. This requires you to have all the data on one machine and know the order.
- Working with many small files: If you’re working with thousands of small files and doing some light processing of the data, having multiple machines might create more work than necessary.
One of the biggest challenges in parallel processing is that some algorithms need to be changed. Think about a decision tree. In a parallel world, you don’t have access to all the data on one machine. So how do you determine the best split?
- Each machine gets a representative sample of the data.
- Each machine evaluates the possible splits on that training set.
- Bring all the possible best decisions together on one machine.
- Evaluate which of these finalist decisions is the best.
- Repeat the process with the updated decision tree.
If you want a really detailed understanding of the decision tree implementation in Spark, take a look at this presentation (slides and video links at the bottom).
Sometimes distributed algorithms have to make smart shortcuts because of the distributed nature of the problem.
Despite some limitations, parallel processing can be done on a wide variety of problems. It just takes more thought on how the algorithm will be implemented. As the user of these algorithms, you should be aware of any shortcuts or nuances that make it different than a single-machine implementation.
For those who want to learn more about adapting machine learning algorithms to work in parallel, try looking at the textbook Mining of Massive Datasets.