Summary: Kaggle competitors spend their time exploring the data, building training set samples to build their models on representative data, explore data leaks, and use tools like Python, R, XGBoost, and Multi-Level Models.

I recently competed in my first Kaggle competition and definitely did not win. A clear lesson in humility for me. I look at the experience as an opportunity to learn about the serious world of applied data mining.
The Kaggle community is full of people who are willing to share their expertise. It’s almost a tradition for users to share their solutions after the end of the competition. Even the top three winners! In aggregate, there are some useful patterns that the everyday analyst can use at work or in competition. I wrote a more statistical analysis of tools used by Kaggle winners. I plan on periodically updating that post with new data.
Set up a good validation set
Kaggle compares your predicted results with a 30% sample of a test set. This lets you see of your model is improving on completely unseen data and is an important step that every analyst should take when developing a model.
However, some of the top Kaggle competitors have called out that the test set “leaderboard” can be misleading and lead to overfitting (in fact one team perfectly overfit the sample test set).
Instead of relying on many checks against that test set sample, the Kagglers will craft controlled samples that are more representative of the data set’s attributes and not rely on simple random samples.
Deep Exploratory Analysis
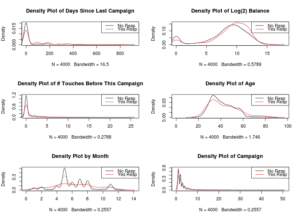
Kaggle allows users to share “Kernels” (i.e. code snippets / notebooks/ reports) that mix code and explanations in one document. You’ll see Kernels that go deep on just a handful of variables in order to find just a few more points of predictive power.
It’s this exploration that seems to lead to major wins in the beginning of a competition. Then comes feature engineering with a good understanding of the attributes you are working with.
This can also take another direction. One that the Kaggle competition organizers don’t always intend…
Data Leakage
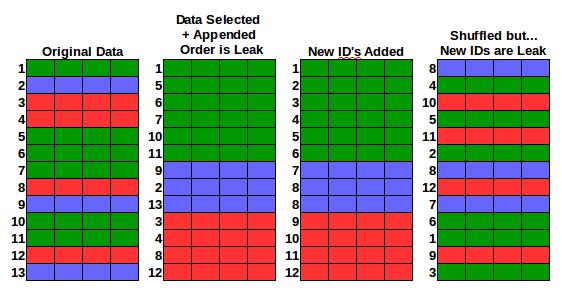
The purpose of a Kaggle competition is to derive some new model for the sponsor. However, whenever there is a cash prize involved, someone is always looking to game the system.
A data leak can include:
- The order of the training and test set.
- Attributes of the ID columns.
As part of the exploration, a Kaggle-competitor might spend time looking at the order of the training an testing sets, looking for data duplication, or building features on top of the different parts of the ID.
This still takes a level of skill but definitely detracts from the business goal of finding a new model that could be applied.
Where are the Tools?
I see mainly Python and some R being used to create models for Kaggle competitions but there’s an occasional deep neural network. Especially from the competitors who are in PhD programs at this time.
There are some consistent algorithms being used across competitions.
XGBOOST
eXtreme Gradient BOOSTing is a defacto tool that top Kaggle competitors use in their models.
It is an ensemble technique that combines many decision trees to build a more accurate model. The XGBoost algorithm is available in both Python and R.
Multi-Level Models

Another very common modeling method is to train many models(dozens) and then use the predictions as input to another model.
Think about it in terms of a neural network. You have your input layer, an activation layer, and an output layer. You might extend that to have a second activation layer that continues to find new combinations.
The benefit to these sorts of models is that you can use many different models and blend their strengths and weaknesses.
From several of the winners, I have seen XGBoost used both as an input and as an activation / combination layer model.
Further Reading
If you’d like to read the results for yourself, here is a small collection of solution discussions.