P-Values and Z-Scores
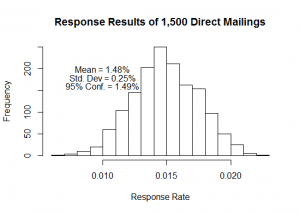
A P-Value represents the probability that the data you have collected is due to chance. This helps you determine whether or not there is a real difference between your observations and the norm. The P-Value is calculated by converting your statistic (such as mean / average) into a Z-Score. Z = (X – AVG(X) ) […]