Summary: Dean Wampler from Lightbend presented at the Direct Supply MSOE offices on Tuesday, 4/5/2016. Dean covered a high-level overview of Spark and its benefits (business logic is focus of code and it’s faster). Those wanting to learn more should pick up Learning Spark at O’Reilly books.
Dean’s Slide Deck. Dean’s Books at O’Reilly. Dean’s website / collection of talks.

Meta
- Milwaukee Big Data Meetup was held on 4/5/2016 and graciously hosted by Randy Kirk at the Direct Supply Offices.
- Majority of audience is in the incubator phase of starting a Big Data project.
- Which makes sense when 61% of people talking about Hadoop are just starting out.
- Lots of enthusiasm in the room. Lots of smart people in the room.
- Hoping a few people will volunteer to do at least a brief presentation in the future!
- Dean recommended Learning Spark as the book to start with.
About the Speaker: Dean Wampler
Dean Wampler (LinkedIn) is a three time author, Spark contributor, and CTO at Lightbend. Dean is more involved in the Chicago Hadoop community. He made a special trip up to Milwaukee on April 5th in order to present on his experiences.
Dean was an excellent speaker and obviously well versed in the history, strengths, and weaknesses of the many big data technologies available today. He even created a Spark Workshop project on GitHub for those getting started.
Personally, I appreciated his emphasis on the elegance of Scala (and functional) code. A key component to his presentation was how bulky a java MapReduce script is relative to a Scala Spark script (lots of references to sacrificing chickens to the Hadoop gods).
Key Takeaways
Based on some post-presentation conversations, everyone took away a little something (a little inspiration, more confidence, some new contacts, etc.). Here are some of the key ideas I walked away with.
The Big Data Environment

- Functional programming takes programming back to its mathematical roots.
- Big Data is the killer app for functional programming.
- For R programmers, we should check out H20.ai.
- The environment has been changing and maturing
- MapReduce was a pain to write in Java.
- Hive (SQL-like tool) was one of the first higher level languages to abstract MapReduce code.
- PIG came out of Yahoo and offered some more data transformation.
- Scalding was elegant but suffered from still being batch based.
- Spark and its Scala implementation provides a elegant and concise way to build machine learning pipelines. Business logic is the focus!
Spark!
- Faster than Hadoop, implemented in Scala, works in-memory rather than disk.
- Let’s you use Scala, Java, Python with very few limitations.
- Has SQL support with Hive and its own SQL Context.
- Doesn’t start running until you write a file.
- It uses a Directed Acyclic Graph to keep track of the data flow.
- This is a key feature that allows Spark to be resilient against crashed nodes.
- You can use tools like Jupyter or Zepplin to create scripts.
- The MLlib and GraphX tools, built into Spark, offer machine learning and graph processing for a broad set of algorithms.
- Offers the ability to process streams of data every N seconds.
RDDs and DataFrame API
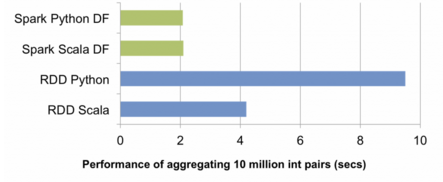
Spark RDD and DataFrame comparison from Databricks’ 2/17/15 blog post.
Dean briefly described Resilient Distributed Datasets (RDDs) and DataFrames in Spark.
- RDDs follow the HDFS model. A file is spread across nodes but acts like one file.
- DataFrames are more like tables with column names you can reference.
- Dean emphasizes using DataFrames when possible.
- They’re faster and more efficient with recent updates (1.5?)
Q&A Session
Question: Does Spark offer bipartite graphs?
- Doesn’t look like a single command / built-in type (SO)
Question: If you’re using Spark’s streaming every N seconds, what happens if your processing takes longer than the N second window?
- Spark will start building a queue of tasks every N seconds.
- However, if it never picks up speed in processing, eventually you’ll run out of memory.
Question: For new Big Data users, do most people start with an IT project or a business project?
- Most people start out with an IT related project (storing or processing data).
- Even if you start with a business problem, you have to solve the IT issues anyway.
- Most people starting out can just spin up some clusters on AWS
Question: Are there features not yet implemented in the Python implementation of Spark?
- Per Dean, Python should be pretty much all caught up by now.
Bottom Line: Great meetup! Great discussion afterwards. Learned a few new things and walked away charged for more.