Pyspark Joins by Example
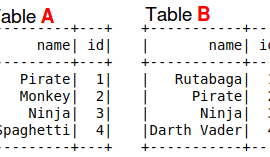
Summary: Pyspark DataFrames have a join method which takes three parameters: DataFrame on the right side of the join, Which fields are being joined on, and what type of join (inner, outer, left_outer, right_outer, leftsemi). You call the join method from the left side DataFrame object such as df1.join(df2, df1.col1 == df2.col1, ‘inner’).