K-Nearest-Neighbors is used in classification and prediction by averaging the results of the K nearest data points (i.e. neighbors). It does not create a model, instead it is considered a Memory-Based-Reasoning algorithm where the training data is the “model”. kNN is often used in recommender systems. kNN results are highly dependent on the training data. kNN is also resource intensive due to many distance calculations.
k-Nearest-Neighbors, or kNN, uses the closest data points to predict the class or value of a new object. The power of kNN is that it is very local
Simple kNN Example
Imagine you’re canvasing a neighborhood for an upcoming election. You have last year’s voter records but there are new residents in town. You need to make an educated guess as to which party will they vote for. You can attempt to classify them into one of the two parties by looking at their nearest neighbors.
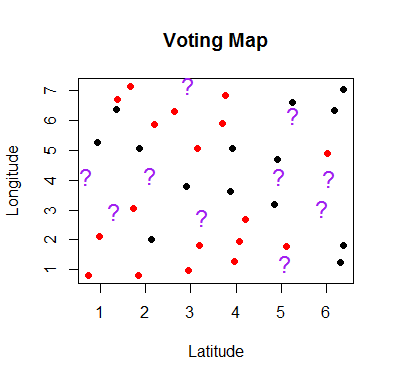
- Red dots are households that voted for political party “X” last election.
- Black dots are households that voted for political party “Y” last election.
- Purple question marks are our holdout set. We know their affiliation but we want to find the right K that helps us predict the classification.
We want to figure out what party we expect the purple question mark households will vote for. Intuitively, we expect that neighbors tend to vote similarly. At least in the United States, people have a tendency to sequester themselves into similarly minded neighborhoods. k-Nearest-Neighbors relies on the distance between objects and makes the assumptions that objects that are close to each other should be the same classification.
kNN requires calculating the distance between the “test” objects (the purple questions marks) and each of the “training” objects (the households with known party affiliations).
With the distances calculated, you take the K closest known objects to the test objects. Then you average the known classifications. For example if you chose K=3 and the top three nearest neighbors were classified as (Republican, Republican, Democrat), you’d guess that the neighbor is likely a Republican. If you chose an even number and there is a tie, you have to arbitrarily break the tie.
Let’s try this on our example data. The charts below show (starting top-left, going clockwise) the actual results for the unknown household, the predictions given one neighbor, the predictions given two neighbors, and the predictions given three neighbors.
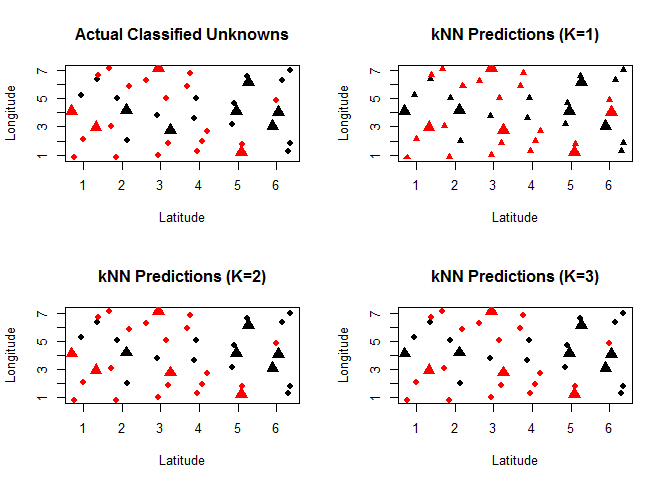
It looks like k=2 has the highest accuracy (9/10). For any future households, we’ll use 2 neighbors to help us determine what party they are likely to vote for.
Speeding up kNN
By it’s very nature, kNN is resource intensive. You have to calculate the distance between a new data point and all other data points with known classification. In lieu of calculating distance for every point, you could first create clusters of your data. Using a method like k-means, which produces cluster centers, an initial distance calculation between the new data and the cluster centers would let you ignore the majority of the data.
lat long 1 2.263528 6.050165 2 5.277356 4.078646 3 2.449602 1.864576
Now instead of calculating the distance for every point, you first calculate the distance between the test objects and the cluster centers. Then you can focus on calculating distances between the test object and objects in that cluster.
However, we have to consider that the edges of two clusters might be closer to the new object. You’ll have to be confident in your cluster separation before applying this method.
Applications of kNN (i.e. Why Learn About kNN?)
Since kNN is memory-based, it’s not an efficient algorithm. You can’t build a representative model and compress the data needed. You have to keep all of the training data in order to make a classification.
However, this doesn’t stop recommender systems from using kNN as a part of collaborative filtering.
Additionally, memory-based methods can be useful when there isn’t a linearly separable class.
kNN Tutorials