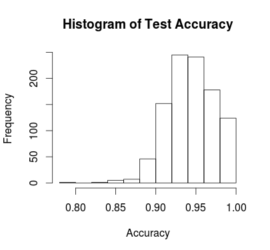
Pyspark ALS and Recommendation Outputs
Lately, I’ve written a few iterations of pyspark to develop a recommender system (I’ve had some practice creating recommender systems in pyspark). I ran into a situation where I needed to generate some recommendations on some different datasets. My problem was that I had to decipher some of the prediction documentation. Because of my struggles, […]