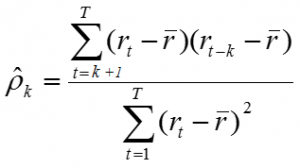Bootstrapping
In data mining, bootstrapping is a resampling technique that lets you generate many sample datasets by repeatedly sampling from your existing data. Why Use Bootstrapping: Sometimes you just don’t have enough data! Statistics requires large amounts of data and repeated samples to be confident in their results. There are two applications of bootstrapping as far as […]