Summary: Every organization should provide their analysts and data scientists with a few key tools: A Data Dictionary, a Metric Dictionary, a Research Repository, and a Code Repository. All of these tools need to be searchable to make it easy for analysts to find and use previous work.
Data and Metric Dictionaries
A big problem large analytical organisations face is the “single question, many answers” inconsistency. Two analysts with equal time at the company can derive two very different answers to the same question based on their experiences and judgement.
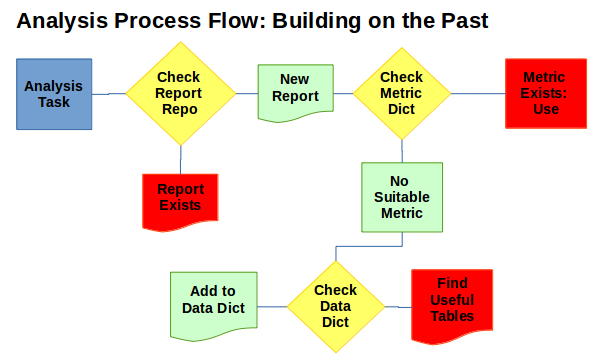
Data Dictionaries Map Where and What Data Are / Is
A Data Dictionary can be as simple as a dump of every table and column to (a much better) comprehensive resource that explains where data exists and what the nuances of the data are.
I’ve spoken with analytical managers who, when asked about their documentation, reference a group of programmers in IT: “If we need to know how some table is built, we just ask them and they can usually find out for us”. Obviously not the right way of doing things.
If I could design my perfect Data Dictionary, I’d include…
- A complete list of tables and columns across all databases.
- Well maintained descriptions, nuances, and transformations on the data before entering the table.
- Mapping of where the data comes from (replication, manual entry, API?)
- Wiki-style maintenance: allowing users and DBAs to interact.
The last point makes life easier for IT since they’re no longer held 100% responsible for maintenance of this collection of tables and attributes. Letting analysts maintain the information keeps the information fresher than IT alone. To prevent vandalism, IT could still maintain a system to approve and deny changes (or hand it over to senior level analysts / business managers).
Metric Dictionaries Help Get One Answer
A new analyst joins your group. You show them the ropes: the core tables, maybe even you share your swipe file or your cheat sheet. Then they’re given their first analysis – maybe one you’ve done a dozen times before. They get a different answer.
The first solution is often emailing your query / code to that analyst.or maybe more training. What if you could prevent that analyst from getting that wrong (or at least different) answer in the first place?
A Metric Dictionary is a single source for how analysts should calculate key metrics.
- Business units should be own the metric definitions.
- The metric should be calculated in the key reporting tools (SQL query, python script, Cognos Cube, Tableau report, etc) to make it accessible to any analyst.
- Metrics should be searchable. Maybe using some sort of StackOverflow clone.
- Metric definitions should be discussed and “better” ways of calculating should be able to filter to the top (e.g. voting system, “sticky” posts).
Given access to a metric dictionary, any new analyst will be able to grab some code and inject it into their report to get a consistent (and accurate) answer.
Research and Code Repositories
From conversations with other analysts, it’s clear that most report results are rarely ever shared beyond a department and maybe make it up to an executive or two. As a result, there are many analysts trying to solve the same problems – not necessarily at the same time.
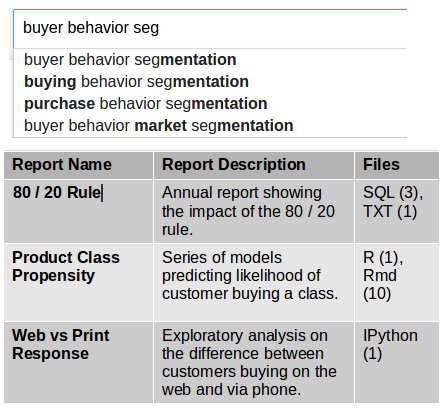
Research Repositories Avoid Duplicate Work
What one manager thinks is a good idea today, another manager might think up this idea a year later. As a result, two analysts will end up doing nearly the same work (especially if they don’t have a metric dictionary). This is not only frustrating for an analyst but it’s also a big waste of time! Companies like AirBnB publish internal research and provide all of the code that goes along with the analysis.
In order to get the most out of internal research there are a few maxims that you should follow.
- Be willing to share your work and make it easy to share (Short URLs rather than attachments).
- Write reproducible analyses (clean code, document, explain data choices).
- Make research easily searchable (avoid PDFs, Word Docs, Powerpoint).
- Create a basic search engine to facilitate searching.
Avoiding duplicate work is a big productivity booster but having easily found previous research also helps analysts and managers look for other avenues in the data. Maybe there was an analysis on customer’s expected lifetime value done. However, that analysis didn’t include some recently discovered key variables.
Another aspect is publishing negative results. Academia suffers from publication bias and it can happen in industry too. Having a public platform (and a motivated analyst) can help encourage others to publish null or negative results. Especially if analysts want to potentially improve their status as a resource in the company (see Aside).
Aside: Getting Meta
There was a great O’Reilly Data Show episode featuring Joe Hellerstein (25:30 to 30:22) which really got me excited about a few ideas for meta analysis. For organizations with a huge number of analysts (and probably a high-turnover analytical groups), here are a few ideas that would be great ways to increase analyst productivity.
- Analyze query logs to identify which tables are often used together.
- Use this information to recommend joins (and ultimately attributes) as analysts are building their queries.
- Identify which users are power users of a given table. These people become resources for other analysts.
- Should probably include more than just frequency of use.
- Maybe how many distinct tables this users joins with this table?
- Maybe how many attributes does the user use from this table?
- Is the report trustworthy and who is using the research (citations)?
Code Repositories (and Version Control)
For any analysis, it’s important to be able to repeat the queries, transformations, and calculations you did the first time. A problem I have noticed is that most analyses are either saved to a users personal PC (I fall in this camp) or somewhere deeply embedded on a company’s network. As a result, if that person isn’t around to find that file it’s back to square one.
The better alternative is to have some sort of central hub for code and project files (that is searchable). GitHub is my favorite example (because it’s web based and easy to use). Tools like JIRA or even SharePoint can serve as a hub. The key ingredients are:
- Searchable to make it easier to know what’s available.
- Keeps a history so you can see if the code (or analysis) is being maintained.
- Stores more than just code: documentation, extra data sets.
- Allows for referencing other projects to avoid duplicating work.
I always think about how new analysts are often dependent on tribal knowledge (knowing who to ask) and having to decrypt someone else’s code and thought process. Having a code repository with well documented code would make new and experienced analysts’ lives easier.
A code repository could easily serve as a metric dictionary as well!
Bottom Line: Great analytical organizations arm their analysts with information that helps build consistent and accurate reports even faster. The biggest productivity tools is as simple as a data dictionary and some version control software to store reports and code snippets.