Building a Recommender System in Spark with ALS
Summary: Spark has an implementation of Alternating Least Squares (ALS) along with a set of very simple functions to create recommendations based on past data.

Summary: Spark has an implementation of Alternating Least Squares (ALS) along with a set of very simple functions to create recommendations based on past data.
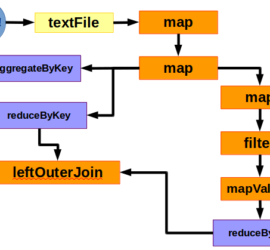
Summary: Spark (and Pyspark) use map, mapValues, reduce, reduceByKey, aggregateByKey, and join to transform, aggregate, and connect datasets. Each function can be stringed together to do more complex tasks.
Summary: The tm and lsa packages provide you a way of manipulating your text data into a term-document matrix and create new, numeric features. The ngram package lets you find frequent word patterns (e.g. “The cow” is a bi-gram or 2-gram; “The cow said” is a tri-gram or 3-gram). Lastly, for a quick visualization (though […]

Summary: The Gini Index is calculated by subtracting the sum of the squared probabilities of each class from one. It favors larger partitions. Information Gain multiplies the probability of the class times the log (base=2) of that class probability. Information Gain favors smaller partitions with many distinct values. Ultimately, you have to experiment with your data […]
As I work on my python script to parse SAS Enterprise Guide projects, I’ve been using git and github to keep track of my changes and keep a stable project while I break things and try to make it better. However, as per my previous post on github, It can be frustrating to work with […]