Writing Quality Data Mining Code
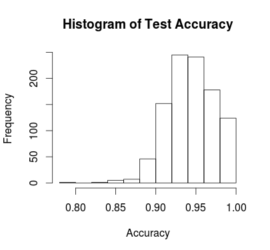
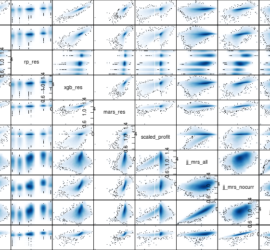
Summary: Writing better quality data mining code requires you to write code that is self-explanatory and does one thing at a time well. In terms of analysis, you should be cross-validating and watching for slowly changing relationships in the data.